Network Root Cause Analysis (RCA) has never been exactly simple. But when networks and IT infrastructure had a simpler architecture, finding a root cause was not overly complex. It was largely either the LAN or the WAN.
Today that relative simplicity has been replaced with ever increasing complexity. Nowadays, we still have LANs, but they often connect servers to other servers and then feed wireless access points which are how end users get to the network.
At the same time, computing is now more distributed. Applications reside both in-house and in the cloud, and some of these are hybrid so the processing is shared between the two. And rare today is the on-premises server that is not virtualized. This turns one server into many and makes it more difficult to find which VM is causing the problem.
Plus, today’s critical applications serve users in multiple departments and spanning various geographic locations.
Meanwhile, the problems admins attempt to define are varied. Some are deal breakers where the network or an application is brought down. Others involve slow performance ―issues that can be harder to trace.
But wait – it gets even worse. More and more hackers, with increasing sophistication, are regularly stepping up their attacks. These issues are on top of the normal breakdowns that occur with complex network, server and application infrastructure.
The Problem with Silos
RCA is still the answer to many IT problems, and this search is best kicked off by a solution that creates alarms that are triggered by a system that is enabled by both broad and deep visibility into the network and services.
Unfortunately, traditional monitoring tools tend to operate in silos. They are often focused on on-premises networks, specific applications (including cloud apps), OSes, virtual servers, or bits of network gear such as routers and switches. This makes it tough for system admins to pinpoint the root cause of complex, and often deeply hidden, problems.
IT needs to know exactly what they are monitoring if they are going to be able to fix it. And it is far more efficient to have solution that does just that, versus trying to manually sift through the data and alerts from separate siloed monitoring systems. The answer is to have a monitoring and remediation solution armed with a comprehensive visibility into all network and system elements, as well as the applications and services they provide.
Kaseya Traverse is an advanced network monitoring and management solution that offers this level of insight by intelligently discovering your network, starting with completely mapping all Layer 2 and 3 devices and defining the relationships that exists between all these devices. This includes network connectivity, disks, controllers, VLANs, file systems, fibre channel switches, printers, SAN, NAS devices, and more.
Additionally, this process discovers the capabilities, size, capacity, and other key attributes of each element, and goes on to discover applications running on various devices, such as databases, active directory, radius, DNS, mail, and application servers.
A Service-Centric Approach
Traditional network monitoring and remediation tools focus on network components. That may have worked well in the past, but organizations today are laser focused on business uptime and that means keeping services running and operating with proper performance.
The right solution lets IT focus on spotting service problems ― not just infrastructure problems ― then diagnosing and ultimately repairing the issue. So instead of just asking if the routing table needs work, IT looks to see if business services such as ERP or CRM are working properly, and if not, why.
With Kaseya Traverse, IT staff can view even the most complex infrastructure based on service-level views. This service-oriented view enables fast root cause analysis, so network and service problems, especially regarding the cloud, are quickly resolved and don’t hold operations up.
One way to explain this is by referencing the traditional seven-layer OSI network model. With Traverse, instead of just looking at just the lower network layers, you can examine the upper layers, all the way up to Layer 7 – the Application Layer.
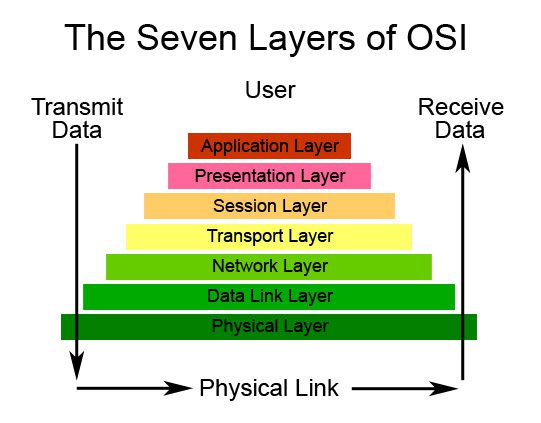
The right solution systematically troubleshoots all the layers that support any particular service. In many cases, a problem will initially present at a high layer such as Application. In this case, IT drills down deeper and deeper to discover and isolate the true root of the problem – all the way down to the details of network flows. With this approach, IT narrows down the problem as it moves through the layers. The challenge in complex, dispersed infrastructures is that finding all the IT components that support the application is non-trivial. Finding which router supports which service, for example, can take hours or even days.
Traverse’s service container technology enables IT and business personnel to create unique virtual views of discrete business services – again, including all OSI layers. This way, IT can quickly spot all relevant components to discover the underlying issue. In fact, Traverse makes the alignment of infrastructure technology with business outcomes a reality. Because IT can now see the entire landscape for any application or business service, they can be more proactive and preventative with Traverse rather than reactive. Traverse facilitates decentralized remote infrastructure management, giving all employee levels the control and information they need to do their job based on their specific responsibilities and permissions.
Traverse lets IT create flexible “containers” of applications, devices or tests in order to see the end-to-end performance of a “service.” For example, a “Payroll service” might have a database, a printer, and a payroll application all connected via a network router. This feature allows the user to create a “Payroll Service Container” and monitor all underlying components of that service in a single view. The status of the containers is updated in real time based on the status of its components.
The object-oriented components of the Traverse architecture are capable of automatically determining relationships between problems in the infrastructure and business services. Service containers can also be created to represent a geographic location, a business unit, or a revenue-generating service. Containers can share elements with other containers. Meaning? Traverse finds the connections; IT no longer has to spend hours, days or weeks creating maps of their infrastructure.
The Traverse Customer Experience
One customer believes that Traverse keeps them on the leading edge. “The monitoring needs of leading edge companies have evolved due to the rapid adoption of cloud services. Legacy tools simply can no longer keep up,” said Sunil Bhatt, CTO of Allied Digital. “With innovative capabilities such as integrated multi-tenant net-flow, network configuration management and SLA modules, Kaseya Traverse offers an integrated, unified monitoring solution for the new generation of digitally transformed companies.”
Learn more about Kaseya Traverse here.





