U.S. agencies warn of PLC attacks as Microsoft phishing spreads and Google Chrome zero-day is actively exploited.

The week in breach news
April 15th, 2026
U.S. agencies warn of PLC attacks as Microsoft phishing spreads and Google Chrome zero-day is actively exploited.

Learn how security information and event management (SIEM) helps organizations proactively identify and address potential security threats and vulnerabilities.
Big names hit this week as the FBI labels a “major incident,” while Hasbro, Cisco and Nissan face cyberattacks.

In an era of relentless cyberattacks, infrastructure complexity and rising client expectations, simply having backups is no longer enough. BackupsRead More
The European Commission breach exposed 350 GB of data, while a Texas school district was locked out of its systems in a suspected cyberattack.
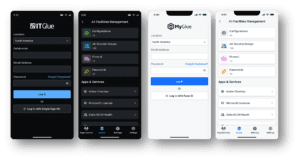
Explore the latest IT Glue UX updates designed to simplify workflows, improve usability and help teams access and manage documentation faster.

If you’ve ever built a Quarterly Business Review (QBR) from scratch — again and again — you already know theRead More
A California city declares a state of emergency due to ransomware, while Microsoft warns of a growing Teams vishing campaign.

Ensure your organisation is prepared to withstand security threats and recover from incidents. Read the blog to learn about the ten key areas to consider for NIS2 compliance.